
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 코드트리
- OOP
- 네트워크 기초
- 데이터 마이닝
- numpy 기초
- 자바
- 코딩테스트
- lambda
- 머신러닝
- c++
- 넘파이 기초
- 데이터 분석
- java
- 클러스터링
- python
- cpp
- 기계학습
- 파이썬
- cpp class
- 디자인 패턴
- ack
- Design Pattern
- Machine Learning
- 넘파이 배열
- 코테
- 코딩테스트실력진단
- NumPy
- 넘파이
- 합성곱 신경망
- 차원축소
- Today
- Total
준비하는 대학생
[Deep Learning] Activation Function (활성화 함수) 본문
활성화 함수는 인공신경망에서 비선형성을 도입하여 복잡한 함수를 모델링하는 데 필수적인 요소입니다. 여기서는 널리 사용되는 몇 가지 활성화 함수들을 살펴보고, 이들의 특징과 수학적 표현, 코드 구현 및 그래프를 통해 각각을 자세히 이해할 수 있도록 하겠습니다.
계단 함수(Step Function)
계단 함수는 가장 단순한 형태의 활성화 함수입니다. 입력값이 0보다 작으면 0을, 그렇지 않으면 1을 출력합니다. 하지만 이 함수는 동일한 출력을 가질 수 있는 다양한 입력값들에 대해 구분을 할 수 없다는 단점이 있습니다. 예를 들어, 시험 점수가 60점 이상이면 합격, 그렇지 않으면 불합격으로 처리하는 경우, 59점과 0점은 차이가 있음에도 불구하고 둘 다 불합격으로 분류됩니다.
import torch
import matplotlib.pyplot as plt
x = torch.arange(-5., 5., 0.1)
y = torch.where(x < 0, torch.tensor(0.0), torch.tensor(1.0))
plt.plot(x.numpy(), y.numpy())
plt.title('Step Function')
plt.grid(True)
plt.show()
시그모이드 함수(Sigmoid)
시그모이드 함수는 실수 입력값을 (0, 1) 범위로 압축하여 출력하는 활성화 함수입니다. 이 함수는 모든 실수에 대해 미분 가능하며, 출력값의 범위가 0과 1 사이로 제한되기 때문에 주로 이진 분류 문제에서 출력층에 사용됩니다. 그러나 큰 양수나 음수에 대해서는 그래디언트가 거의 0에 가까워지는 소실 문제가 있습니다.
$$f(x) = \frac{1}{1+e^{-x}}$$
import torch
import matplotlib.pyplot as plt
x = torch.arange(-5., 5., 0.1)
y = 1 / (1 + torch.exp(-x))
plt.plot(x.numpy(), y.numpy())
plt.title('Sigmoid Function')
plt.grid(True)
plt.show()
하이퍼볼릭 탄젠트 함수(Tanh)
하이퍼볼릭 탄젠트 함수는 시그모이드 함수와 매우 유사하나, 출력 범위가 (-1, 1)로 조정된 활성화 함수입니다. 이는 결과값을 중심화시켜 기울기 소실 문제를 일부 해결하는 데 도움을 줍니다. 그러나 여전히 큰 입력값에 대해서는 포화 문제가 남아있습니다.
$$f(x) = tanh\ x =\frac{e^x-e^{-x}}{e^x+e^{-x}}$$
import torch
import matplotlib.pyplot as plt
x = torch.arange(-5., 5., 0.1)
y = torch.tanh(x)
plt.plot(x.numpy(), y.numpy())
plt.title('Tanh Function')
plt.grid(True)
plt.show()
ReLU 함수(Rectified Linear Unit)
ReLU 함수는 현재 가장 널리 사용되는 활성화 함수입니다. 음수 입력에 대해서는 0을, 양수 입력에 대해서는 입력값을 그대로 출력합니다. 이 함수는 그라디언트 소실 문제를 크게 완화시키며, 연산 비용이 낮아 빠른 학습이 가능합니다.
$$f(x) = max(0,x)$$
import torch
import matplotlib.pyplot as plt
x = torch.arange(-5., 5., 0.1)
y = torch.maximum(torch.tensor(0), x)
plt.plot(x.numpy(), y.numpy())
plt.title('ReLU Function')
plt.grid(True)
plt.show()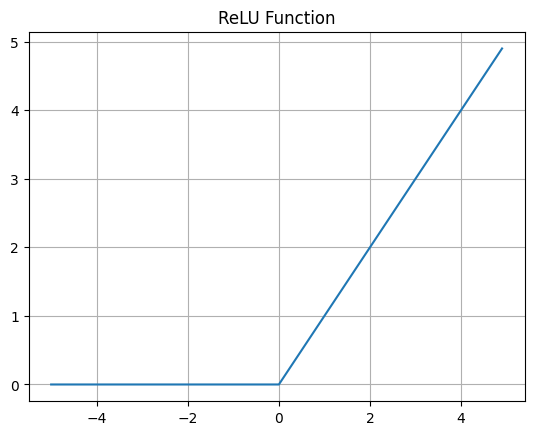
PReLU 함수(Parametric ReLU)
PReLU 함수는 ReLU의 변형으로, 음수 입력에 대해서도 기울기가 완전히 0이 되지 않도록 작은 값을 출력합니다. 이는 "죽은 ReLU" 문제를 해결하여 네트워크의 일부 출력이 항상 0이 되어버리는 문제를 완화합니다.
$$f(x) = max(x,ax)$$
import torch
import matplotlib.pyplot as plt
prelu = torch.nn.PReLU(num_parameters=1)
x = torch.arange(-5., 5., 0.1)
y = prelu(x)
plt.plot(x.numpy(), y.detach().numpy())
plt.title('PReLU Function')
plt.grid(True)
plt.show()
소프트맥스 함수(Softmax)
소프트맥스 함수는 주로 다중 클래스 분류 문제의 출력층에서 사용됩니다. 입력된 벡터를 확률 분포로 변환하여, 각 클래스에 속할 확률을 출력합니다. 모든 출력값의 합은 1이 됩니다.
$$softmax(x_i) = \frac{e^{x_i}}{\sum_{j=1}^{k}{e^{x_j}}}$$
import torch.nn as nn
import torch
softmax = nn.Softmax(dim=1)
x_input = torch.randn(1, 3)
y_output = softmax(x_input)
print(x_input)
print(y_output)
print(torch.sum(y_output, dim=1))tensor([[-2.3327, 0.4099, 2.0931]])
tensor([[0.0100, 0.1551, 0.8349]])
tensor([1.])이러한 활성화 함수들은 신경망이 다양한 패턴을 학습하고 복잡한 문제를 해결할 수 있도록 돕습니다. 각 함수의 특징을 이해하고 적절한 문제에 적절한 함수를 사용하는 것이 중요합니다.
'Programming > NLP' 카테고리의 다른 글
| [자연언어 처리] CNN 핵심 요소 (0) | 2023.11.25 |
|---|---|
| [자연언어처리] 피드 포워드 신경망(MLP, CNN) (2) | 2023.11.25 |
| [자연어 처리] 웹 스크레이핑 기초 - 1 (0) | 2023.09.14 |
